模型结构
K近邻(K Nearest Neighbor)是一种基于存储的算法,该算法不需要拟合任何模型,给定一个需要判别的样本$x_{i}$,KNN算法会在数据库中搜索与$x_{i}$最近的数据或$k$个最近的数据来判别$x_{i}$。特别地,当$k=1$时,KNN就退化成最近邻(Nearest Neighbor)算法,也等同于原型方法,其中每一个样本点都是一个簇中心。由于KNN算法是基于距离的算法,因此影响该算法表现的至关重要的两点有:1. 距离度量的方法;2. 数据各特征的尺度差异。对于第二点,一般对数据进行Standardization变换,使得所有特征服从标准正态分布。可以证明(智商不够),最近邻算法的误差率近似不会超过贝叶斯误差的两倍。
当KNN应用于高维数据时,问题也随之而来。首先是随着维度的增加,数据点在空间的分布会很稀疏,“最近邻”的概念被淡化;另一个问题是应用最广泛的欧氏距离并不是一个通用的距离度量方法。考虑下图所示的情况:
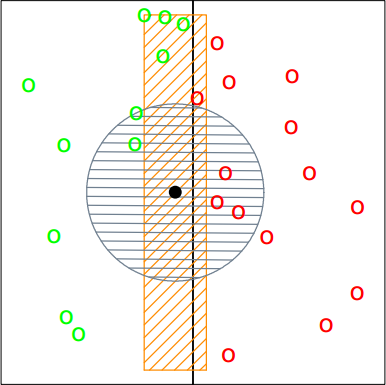
图中黑点是需要预测的的点,长条区域表示的是只考虑$y$轴距离的5个最近领样本,圆形区域表示的是考虑所有维度距离的5个最近领样本;前者正确分类,后者反而造成了误分类。要减缓这种问题也很简单,将$x$轴的尺度放大或者将$y$轴的尺度缩小即可。一般来说,我们会拉伸类分布概率变化不是很剧烈的那个轴。如上图的例子,$x$轴上的类分布概率是一个形如符号函数的分布,而在$y$轴上的类分布概率则是随机的,那我们就拉伸$x$轴。
KNN算法其实很简单,没什么好讲的,唯一值的一提的就是可优化的地方,用K-D树可以减少该算法的计算复杂度。